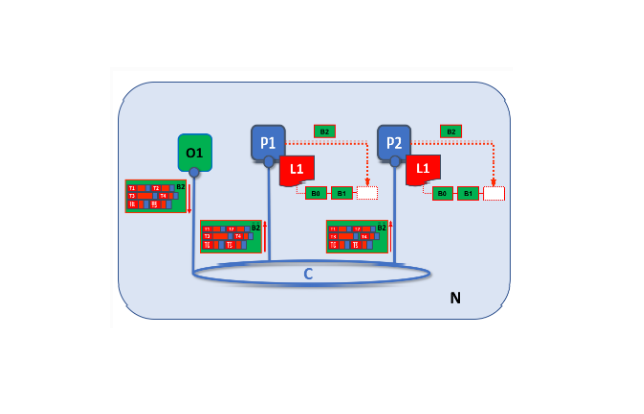
1. Orderer
기본 비트나 이더리움은 아무 node나 transaction의 순서를 정하고, block으로 묶는다.
비트나 이더리움은 높은 확률로 ledger의 일관성을 보장하는 "확률론적 알고리즘"을 채택하기 때문이다.
ledger가 fork가 되면 참여자들이 서로다른 trnasaction 순서를 가질수도 있다.
fabric은 orderer가 transaction의 순서를 관리하는것이 기존 비트, 이더와의 차이점이다.
이는 orderer가 결정하는 결정론적 알고리즘이다.
그렇기 때문에 peer가 검증한 모든 블록은 최종적이고 정확함을 보장한다. => fork되지 않는다.
이외에도 순서화와 체인코드의 실행을 orderer와 peer로 분산시켰기 때문에 성능과 확장성 측면에서 이점을 얻을수 있다.
피어와 마찬가지로 오더러는 노드 조직에 속하기 때문에 오더러는 별도의 인증 기관을 사용한다.
2. Orderer nodes and Channel configuration
오더러는 정책을 기반으로 데이터를 읽고 쓸 수 있는 사람과 채널을 구성할 수 있는 사람을 제한한다.
오더러는 요청자의 권한을 확인한 후 검증이 되면 새로운 구성 트랜잭션을 생성한 뒤 채널의 모든 피어에 전달될 블록으로 패키징 한다.
3. Transaction flow
(1) 제안
애플리케이션은 신뢰할 수 있는 피어를 통해 Fabric Gateway 서비스에 트랜잭션 제안을 보낸다.
이 피어는 트랜잭션을 실행하거나 실행시키기 위해 조직의 다른 피어에게 전달한다.
게이트 웨이도 보증 정책에 필요한 조직의 동료에게 트랜잭션을 전달한다.
보증피어는 트랜잭션을 실행하고 게이트웨이에 트랜잭션 응답(propesd update)을 반환한다.
지금은 제안된 업데이트를 원장 사본에 적용하지 않는다.
(2) 트랜잭션 제출
제안이 완료되면 애플리케이션은 서명을 위해 게이트웨이로부터 승인된 트랜잭션 제안 응답을 받는다.
애플리케이션은 오더러에게 게이트웨이를 통하여 오더러에게 서명된 트랜잭션들을 제출한다.
오더러는 받은 여러개의 트랜잭션들을 블록으로 패키징한다.
한 블록의 트랜잭션 개수는 채널 설정(크기, 허용시간)에 따라 달라진다.
블록에서 트랜잭션의 순서는 오더러가 받은 트랜잭션의 순서와 반드시 동일하지는 않다.
중요한점은 오더러가 트랜잭션의 순서를 정하고 피어가 이 순서에 따라 재검증하고 커밋한다는것이다.
이러한 순서를 매기는 과정이 fabric이 다른 블록체인과의 다른점이다.
다른 불록체인에서는 종종 똑같은 트랜잭션이 다른 블록으로 각각 패키지되어 체인 연결 경쟁을 한다.
반면 fabric은 오더러가 만든 블록이 최종 블록이 된다.
트랜잭션이 블록에 기록되면 ledger의 위치는 불변으로 보장되기 때문에 fork가 없음을 의미한다.
검증되고 커밋된 트랜잭션은 되돌리거나 삭제되지 않는다.
(3) 검증 및 커밋
오더러는 모든 연결된 피어들에게 블록을 분배한다.
피어는 gossip프로토콜을 사용하여 다른 피어에게 블록을 받을수도 있지만 오더러에게 직접 받는것이 좋다.
각 피어는 분산된 블록을 독립적으로 검증하여 ledger의 일관성을 유지한다.
구체적으로 채널의 각 피어는 '허가된 조직에서 보증했는지', '보증이 일치하는지', '최근 커밋된 다른 트랜잭션에 의해 무효화 되지 않았는지' 등을 확인한다.
무효화된 트랜잭션은 오더러가 생성한 블록에 유지는 되지만 피어에 의해 유효하지 않은것으로 표시되어 ledger의 상태를 업데이트 하지 않는다.
즉, 오더러에서 패키징한 블록은 모든 ledger에 일관되게 반영된다.
블록을 정렬하면 각 피어가 트랜잭션 업데이트를 채널 전체에 일관되게 적용하는지 확인할 수 있다.
4. Ordering service 구현
오더러는 기본적으로 동일하게 트랜잭션을 처리하지만 엄격한 순서 지정에 대한 합의를 달성하기위해 분류할 수 있다.
(1) Raft
채널의 오더러 노드 중에서 리더가 동적으로 선출되는 리더 및 팔로우 모델을 사용한다.
CFT(crash fault tolerant) 구현 방식으로 주문노드가 남아있는 한 시스템은 리더 노드를 포함한 노드의 손실을 견딜수 있다.
N/2개의 노드가 남을때 까지 충돌을 버틸수 있다.
예를 들면 서로 다른 세개의 데이터 센터에 하나의 노드를 배치한다.
이렇게 하면 하나의 데이터 센터를 사용할 수 없게 되더라도 다른 데이터 센터의 노드가 계속 작동한다.
(2) Kafka (v2.x에서 더이상 사용되지 않음)
Raft와 비슷한 방식으로 리더 및 팔로우 모델을 사용하고 CFT 방식이다.
(3) Solo (v2.x에서 더이상 사용되지 않음)
단일 오더러 노드로 구성되어있기 때문에 주로 테스트용으로 쓰인다.
5. Raft와 Kafka 차이점
Raft가 설정하기 더 쉽다.
kafka 클러스터와 ZooKeeper 앙상블은 배포하는 것이 까다로우며 인프라 및 설정에 높은 전문 지식이 필요하다.
Raft보다 Kafka로 관리해야 할 구성요소가 더 많기때문에 문제가 발생할 수 있는 부분이 더많다.
Kafka는 오더러와 조정해야 하는 자체 버전도 있지만 Raft는 모든 것이 오더러에 포함된다.
6. Raft 개념
Raft는 항상 팔로워, 후보, 리더 세가지 상태 중 하나에 있다.
모든 노드는 초기에 팔로우로 시작한다.
이 상태에서 리더(선출된 경우)의 로그 항목을 수락하거나 리더에게 투표할수 있다.
설정된 시간 동안 로그 항목이나 하트비트가 수신되지 않으면 노드가 후보 상태로 자체 승격된다.
후보 상태에서 노드는 다른 노드에게 투표를 요청하고 정족수를 받으면 리도로 승격된다.
리더는 새 로그 항목을 수락하고 이를 팔로워에게 복제해야 한다.
7. 스냅샷
오더러 노드가 다운되면 다시 시작할때 놓친 로그를 어떻게 가져오는가?
모든 로그를 무기한 보관할 수 있지만 디스크 공간을 절약하기 위해 Raft는 사용자가 로그에 보관할 데이터 바이트 수를 정의할 수 있는 "스냅샷"이라는 프로세스를 사용한다.
이 데이터 양은 블록의 특정 수를 따른다.
예를 들어 최신블럭이 100인 복제된 R1이 네트워크에 재연결됬다.
리더 L의 블록은 196에 있으며 20개 블록마다 스냅샷을 생성하도록 구성되어 있다.
따라서 R1은 L에서 블록 180을 수신한 다음에 101부터 180까지 블록을 요청한다.
180부터 196 블록은 일반 Raft 프로토콜을 통해 복제된다.
'개발 > HyperLedger' 카테고리의 다른 글
| [Hyperledger] express와 fabric 연결 (gateway구축) (0) | 2023.02.21 |
|---|---|
| [HyperLedger] 네트워크, MSP, Peer (0) | 2023.02.14 |
| [HyperLedger] Fabric 네트워크의 구성 방식 (0) | 2023.01.08 |